Node.js Internals: Not everything happens on the thread pool



One of the biggest misconceptions when it comes to Node is that every asynchronous operation is handled by Libuv’s thread pool. There are numerous articles and diagrams online which tend to explain Node’s runtime architecture and most of them show a standard Reactor pattern, where all the heavy operations are executed by the worker threads. This is wrong. In fact, Libuv uses worker threads only if there is no other way to do things (like it is stated in this and this talk). The purpose of this article is to prove by example that not every asynchronous operation is done on the thread pool.
A little background on asynchronous operations in Node.js
By definition, an asynchronous operation is the one which does not block the thread execution. In other words, if we invoke an asynchronous function, it will execute in the background and control will be returned to the main thread immediately (i.e. the next line will be executed before the async function result is received).
With respect to application code in Node, methods which do not have the “Sync” suffix are considered asynchronous. They will not block the main thread execution. But not all of them are really asynchronous in nature (i.e. not all of them have native async support on the operating system level). Let’s see two examples.
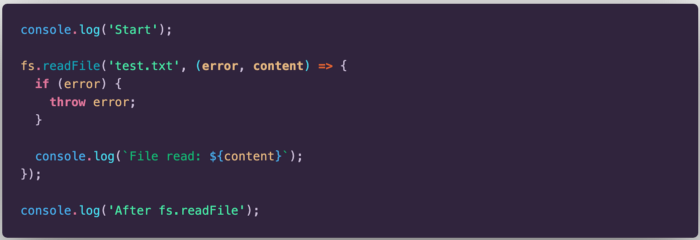
The first snippet is a classic example on how we read small files in Node. The result we get from the execution is the following: “Start” is printed on the console. Then, file read starts. Next, “After fs.readFile” is printed on the console. Finally, file read finishes and the callback is executed. If there is no error, “File read: …” will be printed on the console.
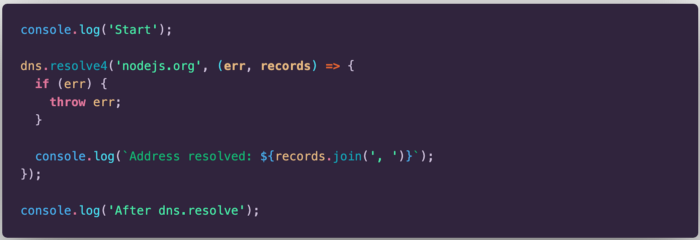
The second snippet uses the resolve4 method from dns module do resolve an IPV4 address. Similarly, it will start by printing “Start” on the console. Then, the resolve4 method is invoked. While address is being resolved, “After dns.resolve” will be logged on the console. Finally, when the address is resolved, the callback will be executed and “Address resolved …” will be printed on the console.
In both cases, the console.log statement will be printed before the callback is even scheduled for execution, which means that both these methods are asynchronous from Javascript’s perspective. However, they differ in the way they are handled. All file operations are executed synchronously on the thread pool, whereas address resolving with dns.resolve is a real asynchronous operation.
Examples
Let’s suppose that we have no prior knowledge on the tasks that are executed on the thread pool and those which are really asynchronous in nature. We will run two examples and study their execution timelines in several cases to draw some conclusions.
Execution environment
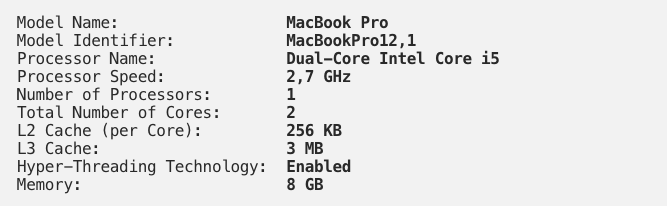
All the snippets are executed on a MacBook Pro with the following specifications:
Example 1: Hashing a password
In this example, we will use the pbkdf2 method from crypto module to generate a hash for a given string. Let’s start with the synchronous version first and see the execution timeline for that.
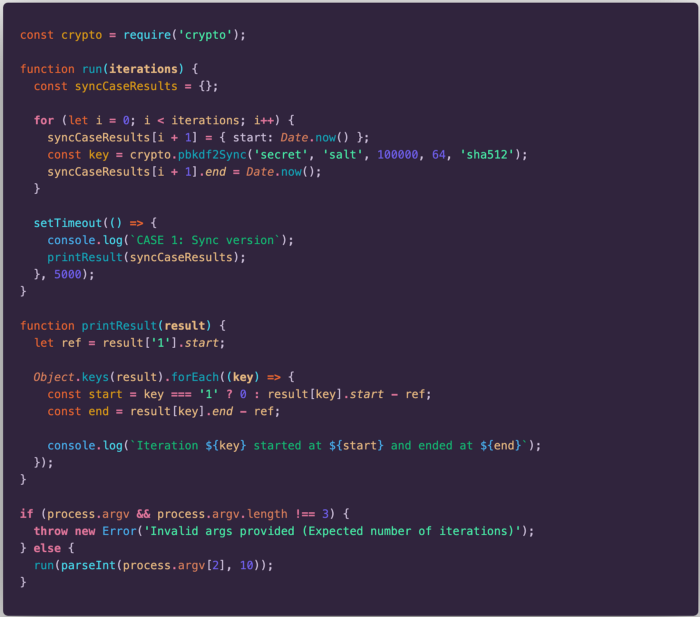
The code above is the full example which also generates the results for the execution times and prints them on the console. In the following examples we will ignore most of it and show only the methods which are executed. Everything else stays the same.
Let’s execute the code above and see what happens for two requests:

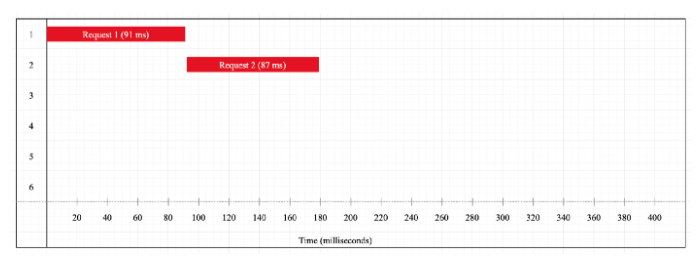
If we take a look at the execution timeline, we see a normal behaviour for synchronous operations. We start with Request 1, which finishes after 91 milliseconds (execution blocks until this request is completed). Soon after that, Request 2 starts and it goes on for 87 ms. Both requests need 179 ms to complete.
Now, let’s slightly modify the code and use the asynchronous version of the method.
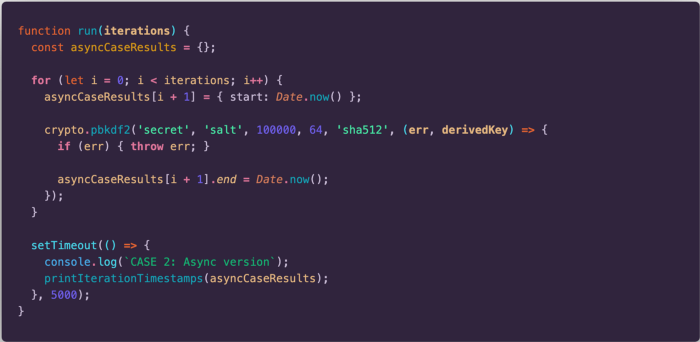
We will execute this code again for two requests. We get the following results:

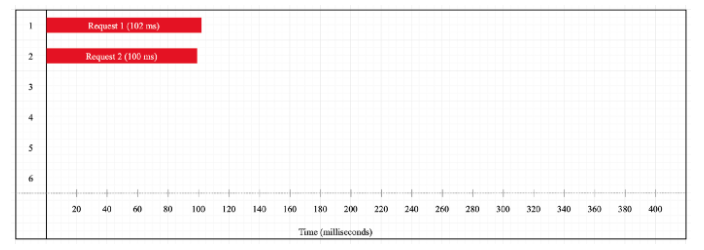
Now we see that the execution timeline has changed and both tasks finish almost at the same time. The total execution time is now only 102 milliseconds (which is equal to the longest running task). Although we do not explicitly use threads on our code, it seems as if something is making our code run in parallel. This is what Libuv does. It uses its worker threads to execute heavy tasks and not block the main thread. Cryptographic functions are one of those types of tasks which are executed on the thread pool. Compared to the first example, the async version takes about half the time, which is why we must always use the async functions whenever possible.
Let’s now increase the number of requests to four. We will get the following result:
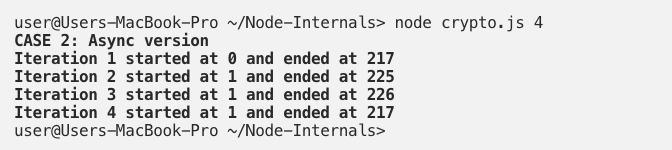
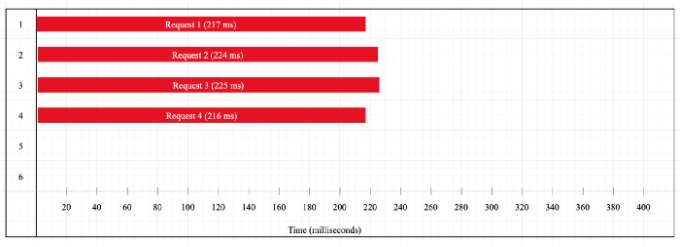
The timeline execution pattern is similar to the previous example (i.e. tasks are executed in parallel). However, we see that the time it takes to complete all requests has increased by a factor of two. There is a reason for that. If we go back to the device specifications, we see that a dual-core CPU is used. Hash generation is a CPU-bound task. Node uses a thread for every request, but since we only have two cores, the four threads will compete for CPU time (two threads per core). Ideally, the execution would take twice the time it takes for two requests, but since there is also some context-switching between threads, the amount of time is slightly more than twice.
Next, we increase the number of requests to six. Let’s see what happens:
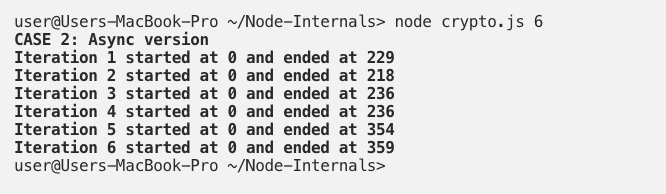
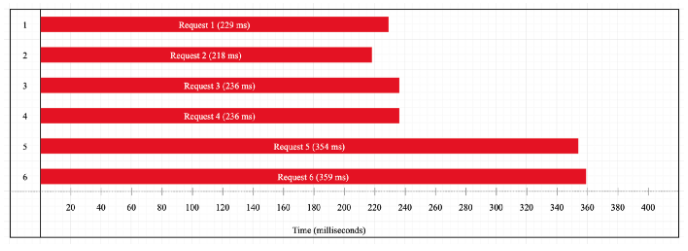
Now we see that the timeline pattern has changed. We have almost the exact same result for the first four requests, but for the last two we have a bigger delay. It seems as if the first four requests are executed in parallel and as soon as they are done, the last two requests start their execution. In other words, the last two requests wait until the first four ones are done and then get their CPU time. This is precisely what happens. To understand the flow, we must know in advance that Libuv uses a pool of only four threads by default. Those four threads are occupied by the first four requests. When they are done, the threads are free to handle the other two requests.
We can change the result above by modifying the default pool size that Libuv uses. We can use the UV_THREADPOOL_SIZE environment variable and set it to 6. Let’s see how this will affect the execution timeline.
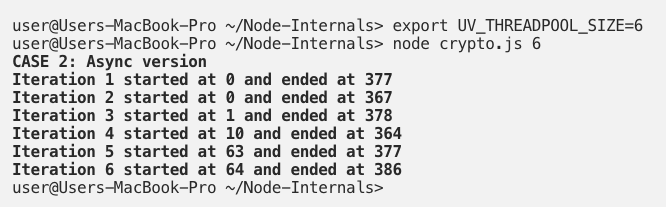
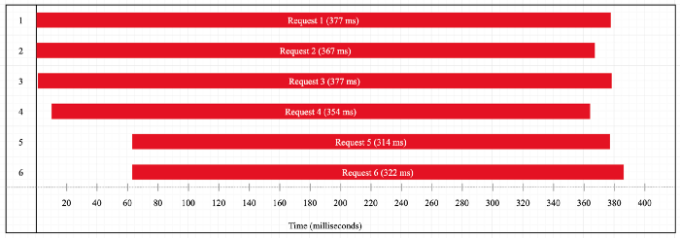
Now we are back to a pattern similar to example 1.3. It is because we now have six Libuv threads that compete for two CPU cores. So, the execution time will be approximately three times the delay it takes for one single request, plus some delay from context switching.
Example 2: Downloading an image
We will repeat the same steps but now we will use the request method from http module. The code that will be executed is shown below (helper functions are omitted since they are the same as the previous example). Very briefly, the code will download the official logo from the Node.js website. When the download is finished (i.e. the “end” event is fired), we will store the end time.
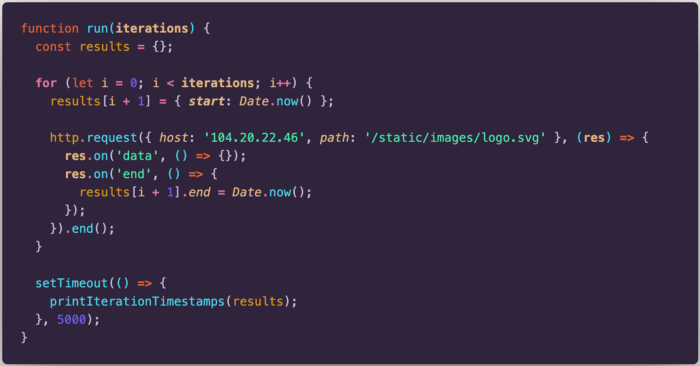
Let’s start by executing this block of code for two requests:

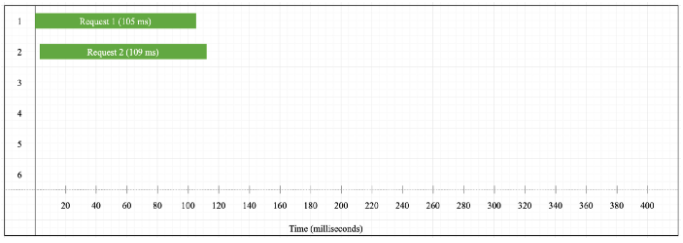
From the execution timeline graph we see that both requests are executed in parallel and they finish after 112 milliseconds. The average execution time is 100 to 110 milliseconds.
Let’s now increase the number of requests to four and see the outcome:

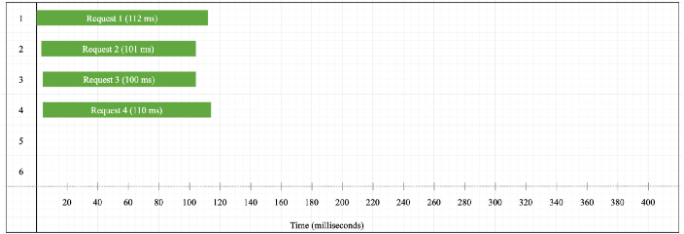
The timeline is similar to the crypto example with four requests. There is one difference, however. The execution time for one request is still the same as in example 2.1 (one request still takes between 100 and 110 milliseconds to complete).
Let’s do one final execution with six requests and see what happens:

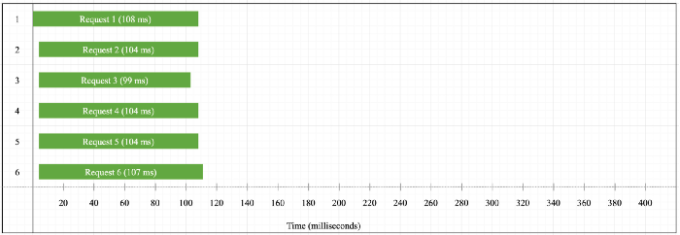
The execution timeline shows nothing new. All six requests are executed in parallel and the time it takes for one request to finish is roughly the same as in the previous cases. This makes us think that this operation has nothing to do with the thread pool. Indeed, this is a network request (i.e. an I/O-bound operation and not CPU-bound) and network I/O does not happen in Libuv’s thread pool. Instead, Libuv will delegate this work to the operating system kernel and whenever possible, it will poll the kernel and see if the download has completed (epoll, kqueue, etc…). The only performance limitation is the network speed, that’s why we see almost the same download time when we have two, four, or six requests.
Conclusion
We used two examples to show two different ways how heavy operations are handled in Node. Whenever possible, Libuv will use native async mechanisms, which makes Node very scalable since the only limitation is the operating system kernel. If there is no other way (e.g. CPU-bounded operations and all file I/O), Libuv will use the thread pool. Although the thread pool preserves asynchronicity with respect to Node’s main thread, it can still become a bottleneck if all threads are busy. This brings scalability problems when applications are mostly CPU-bound. Programmers can learn one useful lesson from all this analysis: If there are performance issues on our application, we can check and see if we can replace functions which use the thread pool with functions which have native async support. One common example is dns.lookup vs. dns.resolve.
APIs which use the thread pool:
- Every filesystem operation (fs module)
- dns.lookup
- Pipes (edge cases)
APIs which are backed by kernel async operations:
- TCP/UDP servers and clients
- Pipes
- dns.resolve
- Child processes
This article is inspired by the following talks:
- The Node.js Event Loop: Not So Single Threaded: https://www.youtube.com/watch?v=zphcsoSJMvM
- Morning Keynote- Everything You Need to Know About Node.js Event Loop — Bert Belder, IBM: https://www.youtube.com/watch?v=PNa9OMajw9w
- NodeConf EU | A deep dive into libuv — Saul Ibarra Coretge: https://www.youtube.com/watch?v=sGTRmPiXD4Y
Full source code and other examples related to the event loop: https://github.com/zeroabsolute/Node-Internals