ResumeGPT: Enhancing Job Seekers' Journey through AI.

Introduction
In today's fast-changing world of web applications, using artificial intelligence (AI) can make a huge difference. This article is about our internal project, ResumeGPT - a special kind of web application built with Next.js and leveraging the power of AI. We built it to make a real change in how people tailor their resumes using AI.
Job hunting can be tricky. You have to make your resume match the job you want so you can have more chances. We realized this was a problem, so we set out to create something different. Our goal was to create a web application that doesn't just make things easier but changes the game.
Right at the center of all this is our use of AI. We wanted our web application to be smart so we built it to understand resumes and job descriptions leveraging OpenAI features. The result? When you upload your resume and the job you're interested in, our site tweaks your resume to match the job better. It's like having a personal coach for your job applications.
In this article, you will find out how we built ResumeGPT using OpenAI.
Keywords
Before we dive into more details, there are some key AI-related concepts you need to know:
- AI Prompt - any form of text, question, information, or coding that communicates to AI what response you’re looking for.
- AI tokens - Tokens can be thought of as pieces of words.
- Fine-tuning - Training an AI model with datasets to get more out of it in terms of accuracy and speed.
Background and Motivation
Imagine you're a job seeker. You find a job you're interested in, and you want your resume to stand out. That's where our project comes in. We wanted to make it easier for you to tailor your resume to match exactly what a job is looking for. With Next.js and AWS, we had a solid foundation. But to make it really smart, we added AI into the mix.
So, the goal was simple: use technology to make the job application process smoother for everyone. This article is about how we went from recognizing a common job-seeking challenge to using technologies, like Next.js and AWS, with a dash of AI, to make that challenge a lot easier to handle.
ResumeGPT Features
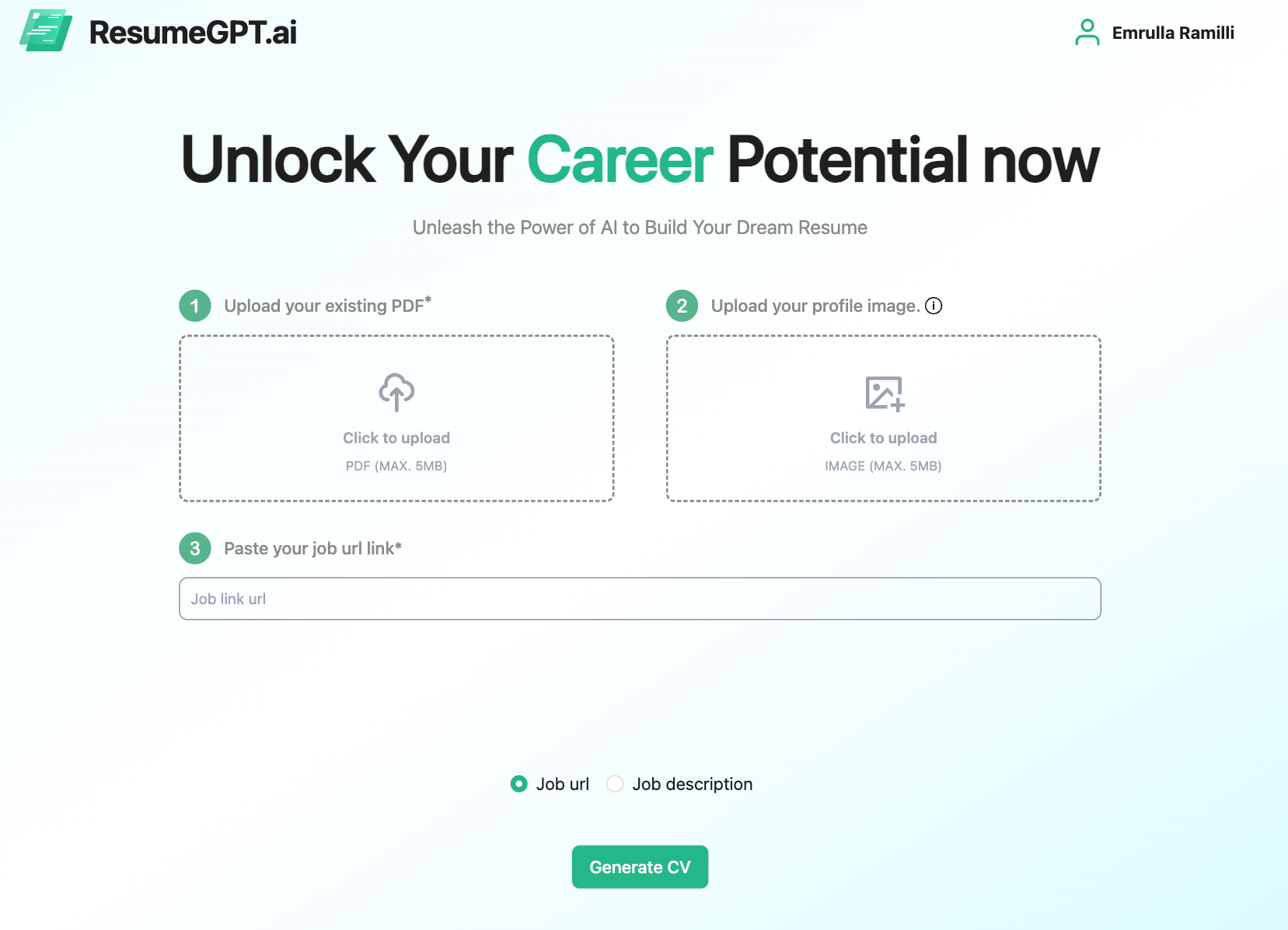
But what does ResumeGPT really do? Below I will describe the user flow mentioning the features that the web application offers.
Every user needs to be authenticated first to access the features. Users can authenticate via email/password or with other providers: Google or Linkedin. After signing up / logging in, the user can now generate resumes with the help of AI or create resumes from scratch for later usage.
Resume Generation
This is the core functionality of the ResumeGPT that is powered by OpenAI. ResumeGPT tailors the resume to the job description responsibilities. How does it work?
The users have the option to upload their CVs and, if they choose, a profile picture. Additionally, they can either enter/paste the job description text or provide the URL link of the posted job. If a link is provided, the system will ensure to extract the job description from the URL. The user will be presented with corresponding error messages in case of any issues.
For each step, there will be a validation:
- If the uploaded resume is not valid (for example: it does not contain experiences or basic user information), the user will be informed that the provided resume is not valid. Therefore, the user needs to upload a new one if they want to continue with the process.
- If the provided job description text or the text from the job link URL is not a valid job description, the user will be shown the relevant error messages.
When the user clicks “Generate”, they can either wait for the process in the web app or they can request the generated resume to be sent via email and can safely navigate away.
After these steps, the processing of the resume and the job description goes through some steps: Extract job responsibilities and skills, parse the resume text into JSON, match experience with the job description, provide a new summary, and in the end, generate the final resume. We will elaborate on these steps later in the article but you can imagine they are analyzed and completed with the help of AI. After the tailored resume/CV has been generated, the user can either download or edit it.
Every part of the CV can be edited. Users can add additional information, remove any redundant details, or even utilize drag-and-drop features to change the layout for each section. Additionally, we have provided users with the option to leverage AI while editing the resume, allowing for suggestions of new experiences or summaries.
After editing, users can download the final product and access the generated resume at any time since they are saved on the user profile page.
Creating a Resume from scratch
Resume creation from scratch is another feature that ResumeGPT provides. This feature offers users the possibility to create a new resume from scratch by adding their own content that they want to be displayed on the resume. The resume layout is the same as the one generated via AI (resume AI generation). After providing the content, users can download the new resume. But it does not end here; they can choose to enhance this resume with AI by providing a job description (similar to the resume generation process). This is where creating resumes from scratch provides an advantage. Since we already have the data in the right format, there's no need to process or extract the data with AI; we just need to enhance the existing content. This process saves a lot of time, and the whole process is much faster than generating a resume with AI by processing an uploaded resume. Users can also access the created resumes in their profile.
Enhance multiple resumes for different jobs
The core functionality of ResumeGPT is to generate a new tailored document based on a job description, as mentioned above. But ResumeGPT also offers the possibility to simultaneously process multiple job descriptions (up to 5) and generate tailored documents for each of the job descriptions. This way, you could easily have your documents for each job description ready in real-time. The waiting time is the same as generating a single document since the user-uploaded information is the same, and the processes are independent of each other, except for the uploaded information and profile picture.
Implementation Details
Software Architecture
We have different modules inside the ResumeGPT such as the web app, resume enhancement module, and job-fetching modules. The web app provides the interface where we get all the user data, and upload the resume, profile picture, and job description. In the sections below, the web app structure is analyzed thoroughly.
The resume enhancement module is all the processing part of the CV that the application does. It goes through many steps to match the content of the CV to the job description and then produces the final generated PDF that the user can edit or download. This is the core feature of the web application as it uses AI for the processing logic.
The job fetching module is related to the feature of accessing the job description via a provided link. This module uses Puppeteer to scrape the web data and is very reliable to extract the job description from the link. This module leverages AI too, as we need to extract the job description from the scrapped text content. The module does not support specific platforms independently. What it does, is that it extracts all the text content from the link (which ideally should have the job description), and then using AI it checks whether there is a job description in the raw text or not. If a valid job description is found, then the process proceeds otherwise an error is shown to the user.
Cloud Infrastructure
Vercel
We deploy our Next JS application to Vercel, which is the best solution for deploying Next JS apps. It offers many advantages, among them is the speed you can put a new feature into production.
Puppeteer - retrieve job description text via URL
Puppeteer is a library used to scrape web data. Using just 'fetch API' in Javascript to get the text content of a website was not enough, as it had some limitations in different platforms. Puppeteer offers a wide range of functionalities in this regard. However since Vercel is a serverless deployment platform, we could not use it with Puppeteer because Puppeteer requires an environment with a local chromium binary, which does not exist on AWS Lambda. So the solution was to create a lambda using some other libraries, specifically puppeteer-extra, puppeteer-extra-plugin-stealth, and @sparticuz/chromium. Another solution would be to dockerize the Next JS application, but this way we would go away from Vercel as it does not support Docker images, but that would not make us better off.
Resume processing and enhancement
The whole process of enhancing the resume, to tailor it to the job description, we have on the AWS Lambda. In this way, the process runs in the background and the user can choose to navigate away from the web application, while the process will run in the background and the user can access the generated file (or files) via email. If the process succeeds, the lambda function executes the logic that sends the generated files via email.
AWS S3
We upload the resume PDF documents into S3 and also store the generated PDFs in another bucket. We also have a retention policy for all the user uploads, storing them for no longer than 1 week in our databases.
AWS RDS
The database runs on the Postgres engine in AWS RDS. We store all the relevant information there.
AWS SES
AWS Simple Email Service is an email platform provided by AWS that lets us easily send emails with different templates. We use SES for email verification, and password reset to notify the user when the CV/resume generation is completed and also provide him/her with the link to the generated CV. If you can recall from previous sections, the latter happens when the user wants to have the final generated CV sent via email.
Web Application Structure
Next JS, the technology for both Frontend and Backend development
Next JS stands out as a formidable frontend React framework, transforming the landscape of web application development with its powerful and well-structured environment. Its intuitive support for client-side navigation, default SEO capabilities, and supplementary features such as image optimization position Next.js as the perfect fit for our application, promising an enhanced and efficient development experience.
Below is a glimpse of our Next Js folder structure for the ResumeGPT project:
/
|-- .next
|-- components
| |-- auth
| |-- signIn
| |-- index.tsx
|-- config
| |-- aws.ts
| |-- openAI.ts
|-- constants
| |-- endpoints.ts
| |-- errors.ts
|-- context
| |-- globalContext.ts
|-- lib
| |-- api
| |-- auth.ts
| |-- user.ts
| |-- resume.ts
| |-- hooks
| |-- useGetApi.ts
| |-- usePdfPreview.ts
|-- middleware
| |-- authenticate.ts
| |-- errorMiddleware.ts
|-- modules
| |-- resume
| |-- resume.controller.ts
| |-- resume.helpers.ts
| |-- resume.service.ts
| |-- resume.validator.ts
| |-- user
| |-- ...
|-- utilities
| |-- convertApi.ts
| |-- dateFormat.ts
| |-- s3.ts
| |-- sendEmail.ts
|-- public
| |-- ...
|-- styles
| |-- global.css
|-- next.config.ts
|-- tailwind.config.ts
|-- pages
| |-- __app.tsx
| |-- __document.tsx
| |-- index.tsx
| |-- login.tsx
| |-- resume
| |-- edit
| |-- [id].tsx
| |-- index.tsx
| |-- api
| |-- auth
| |-- [...nextauth].ts
| |-- resume
| |-- [id]
| |-- ...
| |-- id.ts
Let’s analyze each folder one by one by mentioning the general usage:
.next: This folder is automatically generated by Next JS during the build process and contains compiled assets and metadata necessary for server-side rendering and client-side navigation.
components: Housing reusable UI components such as footer, header, dropdowns, file inputs, etc. In the example given above, the auth folder further organizes components related to authentication, with a signIn subfolder managing the sign-in functionality.
config: Centralized configuration files such as aws.ts and openAI.ts, store settings and credentials for external services, promoting easy maintenance and access across the application.
constants: Essential constants like endpoints.ts and errors.ts consolidate commonly used values and error messages, ensuring consistency and easy updates.
context: The globalContext.ts file contains the global state management logic, providing a shared data layer accessible throughout the application.
lib: The api subfolder handles API interactions, while the hooks subfolder hosts custom hooks, promoting code organization and reusability.
middleware: Storing middleware functions such as authenticate.ts and errorMiddleware.ts, this folder manages logic that runs before or after specific operations, enhancing request handling.
modules: This directory structures the application by features, with the resume and user subfolders containing code related to those specific modules.
utilities: Housing utility functions like convertApi.ts and dateFormat.ts, this folder centralizes miscellaneous helper functions for enhanced code clarity.
public: Reserved for static assets, the public folder stores files like images and documents accessible directly by the client.
styles: The global.css file contains a few global styling rules (as the main styling is made with TailwindCss), mainly influencing the visual appearance of the components from external libraries that cannot be manipulated directly with TailwindCss.
next.config.ts: Configuring Next.js settings, this file allows customizations such as webpack configurations and environment variable definitions.
tailwind.config.ts: Configuring the Tailwind CSS framework, this file provides settings for styling and theming in the application.
pages: Organizing the application's pages, this directory includes files such as __app.tsx and index.tsx defining the app's structure and landing page, respectively. We have created all the pages for resume generation and creation, as its routing system manages the routes for each page based on the relative path to the pages directory.
pages/api/auth: This folder contains the authentication-related API routes. The [...nextauth].ts file handles the authentication routes using NextAuth.js, providing a flexible way to customize authentication logic. More on that in the Authentication section.
pages/api/resume: This folder organizes API routes related to the resume module. The [id] subfolder and id.ts file represent dynamic routing, allowing the handling of specific resume identifiers. The nested structure facilitates a RESTful approach to interacting with individual resumes.
These api folders under pages are a Next.js convention for creating serverless functions and API routes. They provide a simple and integrated way to handle backend logic directly within the pages directory, aligning with Next.js's philosophy of blurring the lines between frontend and backend development.
Authentication
Within the realm of user authentication, our in-depth exploration of NextAuth.js unveils a comprehensive system seamlessly integrating various login methods, including email/password, Google, and LinkedIn. Central to our configuration is the [...nextauth].ts file, where the useSession hook takes center stage, adeptly managing user authentication on the client side and affording easy access to crucial session data within our React components. Adding another layer of sophistication, the useServerSession hook proves instrumental in the management of server-side session data, ensuring consistency across the application.
import NextAuth, {
NextAuthOptions
} from "next-auth";
import GoogleProvider from "next-auth/providers/google";
import CredentialsProvider from "next-auth/providers/credentials";
import LinkedInProvider from "next-auth/providers/linkedin";
import {
NextApiRequest,
NextApiResponse
} from "next";
import bcrypt from "bcrypt";
export function authOptions(req: NextApiRequest, res: NextApiResponse, ): NextAuthOptions {
return {
providers: [CredentialsProvider({
type: "credentials",
credentials: {},
async authorize(credentials) {
...
},
}), GoogleProvider({
clientId: process.env.GOOGLE_CLIENT_ID as string,
clientSecret: process.env.GOOGLE_CLIENT_SECRET as string,
authorization: {
params: {
prompt: "consent",
access_type: "offline",
response_type: "code",
},
},
}), LinkedInProvider({
clientId: process.env.LINKEDIN_CLIENT_ID as string,
clientSecret: process.env.LINKEDIN_CLIENT_SECRET as string,
}), ],
callbacks: {
async jwt({
account,
token
}) {
...
},
async session({
session,
token
}) {
session.user.userId = token.userId as any;
return session;
},
},
};
}
export default async function auth(req: NextApiRequest, res: NextApiResponse) {
return await NextAuth(req, res, authOptions(req, res));
}Parsing the PDFs
The "convertApi" module in our application plays a vital role in transforming PDF documents into accessible text, unlocking opportunities for streamlined data processing. By leveraging specialized libraries such as ConvertApi, this module facilitates the extraction of textual content from PDFs. The converted text then becomes a versatile resource to be used later in the processing logic. In essence, the "ConvertApi" module bridges the gap between the complexities of PDFs and the flexibility of text, enhancing the application's capability to derive insights and improve user interactions.
import ConvertAPI from "convertapi";
import axios from "axios";
import * as process from "process";
const convertApi = new ConvertAPI(process.env.CONVERTAPI_SECRET || "");
export const convertPDFToText = async (filePath: string, ): Promise < any > => {
const convertedResults = await convertApi.convert("txt", {
File: filePath
}, "pdf", );
return convertedResults;
};
export const downloadTextFileFromConvertApi = async (url: string, ): Promise < string > => {
const response = await axios.get(url);
if (response.status !== 200) throw new Error(`unexpected response ${response.statusText}`);
const parsedText = response.data.trim();
return parsedText;
};Templating
The PDFMake library is a powerful tool within our application, enabling dynamic and programmatic generation of PDF documents. This functionality offers a range of possibilities, from generating visually appealing reports to creating downloadable resumes or invoices.
With pdfmake we can define the structure and content of PDF documents using a declarative syntax, making it intuitive and efficient to generate complex layouts. This capability is particularly useful for dynamically creating documents based on user inputs or application data, enhancing the overall user experience. We use it to output user profile images, user skills, experience, skills, and languages.
It actually offers limited styling possibilities but it is a powerful and reliable tool to generate the resumes.
import PdfMake from "pdfmake";
import {
TDocumentDefinitions
} from "pdfmake/interfaces";
import {
getCvHeader,
getCvInfo,
getCvBody
} from "./pdfParts/template";
import fonts from "./fonts";
import {
Resume
} from "./types";
const pdfMake = new PdfMake(fonts);
export const getCvDocumentation = (resume: Resume, profileImage ? : string) => {
const docDefinition: TDocumentDefinitions = {
info: getCvInfo(),
content: [getCvHeader(resume, profileImage), getCvBody(resume)],
};
return pdfMake.createPdfKitDocument(docDefinition);
};Monetization
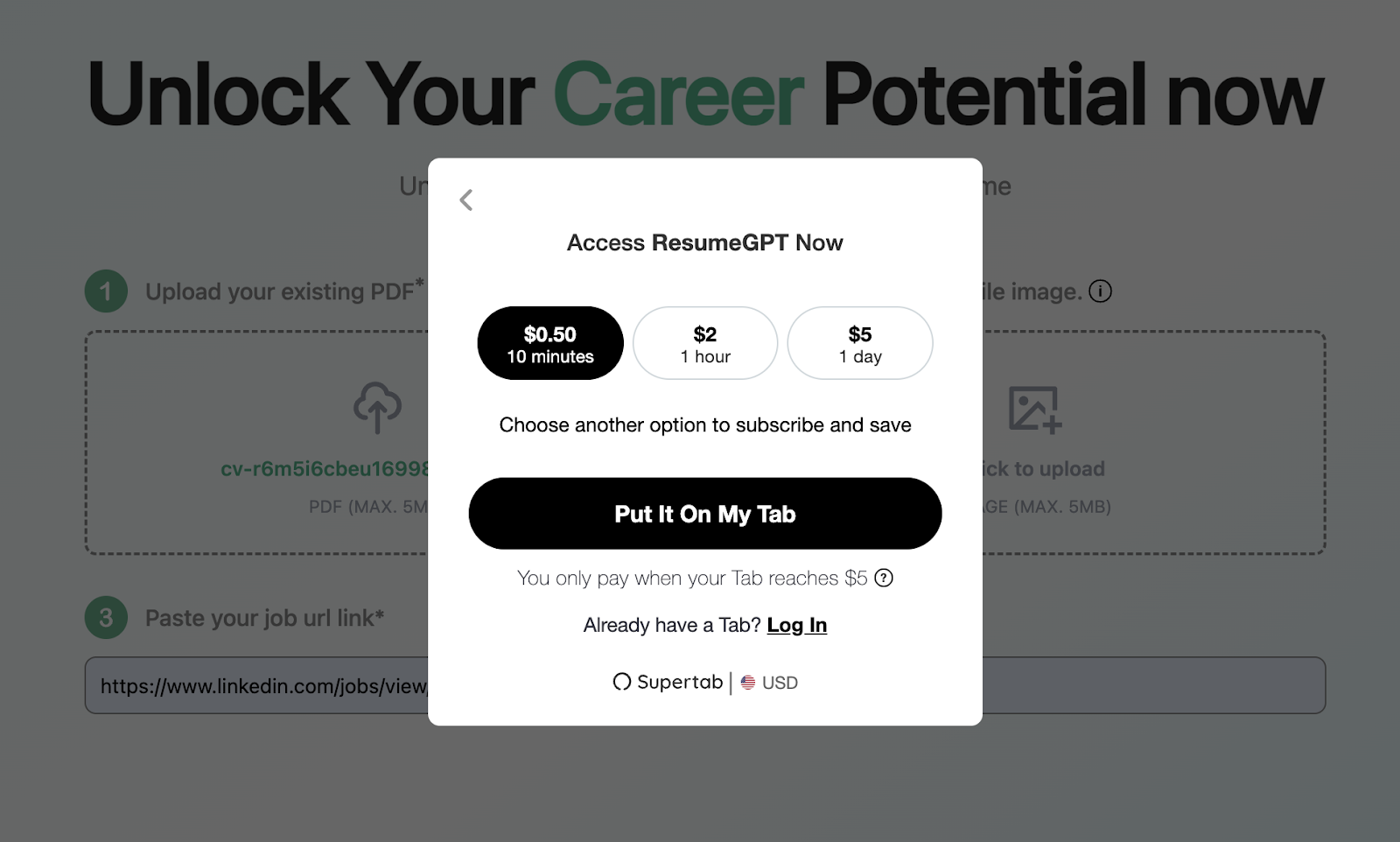
To monetize the app, we have used a platform called Supertab. This platform allows you to make tiny payments possible and then aggregate them when they reach a certain amount. We allow the user to choose one of three options for payment, and the user will be required to pay when his tab (aggregated amount spent) reaches $5. Supertab works by registering with an email account and opening your tab in Supertab. A tab is like a wallet that accumulates the micro-payments you make, and when the tab reaches the threshold of $5, the user must pay that amount to keep using the ResumeGPT features. Learn more about it in this link here.
OpenAI integration
Since the unveiling of ChatGPT in November 2022, the realm of artificial intelligence has undergone a remarkable transformation, profoundly influencing application development. This metamorphosis has not only revolutionized internal processes within companies but has also reshaped the landscape of product delivery. Numerous enterprises have embraced artificial intelligence, embedding it into the core of their operations and leveraging its capabilities to enhance product offerings. The advent of the OpenAI API has played a pivotal role in expediting this integration, providing a user-friendly interface that simplifies and accelerates the adoption of AI technologies.
Significance of AI Integration in Our Project
The pivotal reason behind incorporating AI into our project, ResumeGPT, lies in its ability to revolutionize the traditional approach to job applications. The primary functionality of ResumeGPT revolves around the generation of a curriculum vitae that strategically aligns your skills and work experiences with a given job description. This innovative feature enhances your prospects during the job application process, increasing the likelihood of securing the desired position.
The integration of OpenAI API, specifically leveraging chat-completion capabilities, serves as the technological backbone of our project. By providing the necessary prompts, we dynamically manipulate and customize the content of their resumes, tailoring them to precisely match the requirements outlined in a given job description. This not only streamlines the application process but also significantly elevates the chances of a successful match between the applicant's profile and the job criteria.
How We Harness AI in ResumeGPT
Within the architecture of ResumeGPT, artificial intelligence serves a multifaceted role, seamlessly weaving through various crucial functionalities. Below there are the prompts we use for processing the CV, with some examples of how the prompt looks like.
1. Validation of Uploaded File Content
We employ AI to validate the uploaded file, determining its legitimacy as a resume. This involves extracting the text content using ConvertAPI. The extracted text is then subjected to AI inspection to find out whether it qualifies as a valid resume, meeting the essential criteria of containing basic profile information and at least one work experience.
2. Validation of Job Description
Our AI validates the provided job description, either directly inputted or via a job link URL. The instruction to the AI is clear: identify a minimum of 5 job responsibilities within the description. If the job description qualifies as valid, then we proceed to the next step.
3. JSON Generation from Parsed Text
The essence of CV generation lies in transforming raw text, validated from the CV, into a structured JSON format. This process, pivotal to the overall workflow, adapts fields such as profile, summary, experiences, skills, languages, and more.
4. Extraction of Experiences from CV
AI efficiently extracts work experiences from the CV, forming a comprehensive overview of the candidate's professional background.
5. Extraction of Skills and Responsibilities from Job Description
Our AI logic systematically extracts skills and job responsibilities from the provided job description, contributing to a nuanced understanding of the role's requirements. The prompt should extract 5 top skills and 5 top responsibilities from the job description, and if those cannot be found, then it should be generated by AI based on the job description title and description.
6. Matching Experience with Job
This module doesn't fabricate experiences but intelligently modifies the wording of existing experiences to align with the specific job description, emphasizing relevant details. It generates a modified version of the candidate's experience that aligns perfectly with the given job requirements. In our prompt we also emphasize that the AI should not alter reality, just to emphasize the skills/experience that is relevant to the job description as shown in the prompt below:
“The new responsibilities should emphasize, highlight, and have a bigger focus on the candidate's relevant skills and responsibilities that match the provided job description, without including skills the candidate does not have or things he has never worked with.”7. Calculation of Years of Experience
For each work experience, the system calculates the duration, providing a quantitative measure of the candidate's professional tenure from the start to the end date.
"To calculate the exact number, for each experience subtract StartDate from EndDate. If the end year of one experience is \'present\',\'current\' or something similar that means that the candidate is still working in that job, so the EndDate of that experience is the actual year and month or the last year and month at the Gregorian calendar. Sum all these found differences between StartDate and EndDate up to find the exact total years of experience/work. Calculate the months too if they are written in StartDate or EndDate. If there is a time overlap between the experiences, which means I have been working in 2 jobs at the same time, subtract the overlap time from the result.” 8. Profile Summary Generation:
AI generates a profile summary based on the amalgamation of extracted information, encapsulating the candidate's key attributes and career highlights.
The prompt looks something like this:
“Please generate a concise summary highlighting my key skills, notable accomplishments, and professional background in general without adding details, that will captivate hiring managers. Keep it under 40 words.” 9. Suggestion Mechanisms:
ResumeGPT goes beyond automation, offering suggestive functionalities. This includes proposing alternative profile summaries and suggesting new experiences tailored to user preferences and job requirements. This can be done when the user is editing the resume and wants to have an AI assistant to help him edit some parts of the CV or add new things to enhance it more.
Below is a list of all AI models that we have used throughout our app since the beginning.
- GPT-3.5
- GPT-3.5-Turbo
- GPT-3.5-Turbo-16k
- GPT-4
Now we use only GPT-3.5-Turbo-16k and GPT-4 as they are the most capable models and fit our needs.
Fine-tuning- customizing the model for ResumeGPT
Fine-tuning lets you get more out of the models available through the API by providing:
- Higher quality results than prompting
- Ability to train on more examples than can fit in a prompt
- Token savings due to shorter prompts
- Lower latency requests
How do we use fine-tuning?
We fine-tuned some of the prompts so we could have faster responses. We have built datasets of more than 500 items for the most crucial prompts, which resulted in better results and faster responses. Fine-tuning essentially lets us customize the model for our application. This reduces the costs (as for example we do not need to provide a prompt with examples for the response) and enables lower-latency responses.
Example: How did we fine-tune the ValidateJobDescription prompt?
- Created the dataset in jsonl format. This file is basically a list of JSONs. Each JSON was a full flow of a completion request that would normally happen between the user and Chat GPT for example. A full flow looks like this:
{
"messages": [
{
"role": "system",
"content": "You are an assistant for a company that hires people..."
},
{
"role": "user",
"content": "Here is the provided text that I need you to validate: Jod description..."
},
{
"role": "assistant",
"content": "Got it. I have the text. How can I help?"
},
{
"role": "user",
"content": "Reply only with the result, nothing else."
},
{
"role": "assistant",
"content": "{\"valid\": true}"
}
]
},
{
"messages": [
{
"role": "system",
"content": "You are an assistant for a company that hires people..."
},
{
"role": "user",
"content": "Here is the provided text that I need you to validate: Jod description... different input"
},
{
"role": "assistant",
"content": "Got it. I have the text. How can I help?"
},
{
"role": "user",
"content": "Reply only with the result, nothing else."
},
{
"role": "assistant",
"content": "{\"valid\": false}"
}
]
}
The provided job description above should be a valid one because the end output of the assistant is {“Valid”:” true”}. In another JSON, we would do the same thing but we would change the job description text by providing an invalid job description, and in the end, the final output would be {“Valid”:” false”}.
We should do this for multiple JSONs, the more the better. This way we train the model to be more precise next time we ask him to validate the provided job description. The secret is in dataset size: the larger the dataset size, the more accurate the response is.
2. Integrate the dataset with OpenAI
After we create the dataset file, we need to train a model so we can use it. So, we need to start a fine-tuning job, providing the path of the dataset file we created and the model we want to train for our own purposes.
const fineTune = await openai.fineTuning.jobs.create({
training_file: "file-abc123",
model: "gpt-3.5-turbo"
})3. Using the fine-tuned model:
If the fine-tuning model has been created successfully, we just need to use it by the identifier OpenAI provides us, such as below:
async function main() {
const completion = await openai.chat.completions.create({
messages: [{
role: 'system',
content: "You are a helpful assistant."
}],
model: "ft:gpt-3.5-turbo:my-org:custom_suffic:id",
})
}
main();
Results of Fine-Tunning
After we fine-tuned the models according to our needs and then replaced the modules that we used with the fine-tuned ones, we noticed some obvious improvements.
The answers are more correct with fine-tuning than using the model directly, as the model was inconsistent (rarely but it happened). Fine-tunning was more reliable
The latency was drastically reduced. The latency depends mostly on the prompt provided, the smaller the prompt, the smaller the latency. A process that took 2 min and 30 seconds before we fine-tuned some prompts, after fine-tuning, the time was reduced to 1 minute. More concretely if extracting the JSON from raw text extracted from the CV took 1 minute and 30 seconds for a specific CV with GPT-3.5-turbo, after we fine-tuned the model with our own dataset, the time decreased drastically to 16 seconds.
OpenAI is not free of charge. For every request, there is a cost that depends on the number of tokens (basically words) provided to the prompt. The fine-tuning reduced this cost, as there are fewer words for the prompt.
Learn more about fine-tuning by reading the official documentation.
We are also preparing an article when we go in-depth about fine-tuning, so stay (fine) tuned.
AI Challenges Faced in ResumeGPT
Engaging with OpenAI has presented its set of challenges, a common occurrence when adopting a new tool in the market. However, as we accumulated experience, navigating these challenges became progressively more manageable. Below, we highlight some key hurdles we encountered and addressed during our journey.
Inconsistent Answers
A notable issue we initially encountered was the inconsistency in responses generated by the chat completion feature. Even when using identical prompts, the AI delivered disparate answers. To overcome this challenge, we undertook efforts to refine the completion process. This involved constructing more precise and restrictive prompts while providing specific examples to guide OpenAI in generating responses. Through these adjustments, we successfully enhanced the consistency of prompt generations, resulting in more reliable and dependable outcomes from the AI system. Also, with time, the AI became more consistent.
JSON Formatting and Token Limits in the Resume Generation Process
Parsing the raw text into JSON stands out as a pivotal step in our process, forming the cornerstone on which subsequent actions are dependent. Despite its significance, this step also proves to be the most time-consuming. The entire workflow relies heavily on the JSON structure generated during parsing, as it encapsulates key data from the raw CV text. During the initial phases of constructing the ResumeGPT, a notable challenge surfaced: OpenAI exclusively delivered responses in raw text, not in the desired JSON format. Although we explicitly instructed the AI to provide JSON-formatted responses, inconsistencies persisted. Issues such as special characters, missing quotes, and bracket irregularities necessitated additional checks, including the implementation of the jsonrepair library to correct any mistake. Fortunately, with the advent of newer chat completion models, OpenAI now supports JSON format responses, eliminating the need for manual checks and repairs. This enhancement ensures a more reliable and streamlined process for future iterations.
In managing token limits, a critical aspect to consider is that one token equates to approximately 4 characters in English. For the gpt-3.5-turbo model, the limit is set at 4,096 tokens, while the extended gpt-3.5-turbo-16k model accommodates up to 16,385 tokens. You can find the token limits for each model here. Encountering scenarios where token limits were surpassed was not uncommon, particularly when processing large CVs. This issue prompted us to explore solutions such as condensing prompts for conciseness or breaking down extensive texts into smaller segments. However, the latter approach presented technical challenges, including the need to maintain context when splitting the CV. Fortunately, OpenAI's release of the gpt-3.5-turbo-16k model, with its expanded token limit, proved instrumental. By fine-tuning this model, we successfully addressed the constraints associated with larger CVs, providing a more accommodating solution for our resume generation process.
Calculating Cost (Various Models, Tokens, Average)
One significant challenge revolved around accurately assessing the costs associated with each OpenAI prompt. Given the multitude of models we utilized, this task was far from straightforward. To ensure transparency and efficiency, we needed to meticulously track the tokens used in each step of generating content for our CVs. The token count was influenced by factors such as the input prompt and completion.
OpenAI determines costs based on the number of tokens employed, with distinct costs assigned to each model variant (e.g., 3.5-Turbo, 4). This intricate process demanded a close approximation of token usage to manage and optimize expenses effectively.
The future: ResumeGPT, AI, and more.
We're kicking things up a notch with our product, thanks to the awesome feedback from our users. Brace yourselves for some cool updates – improved multiple CV generation flow by inserting at maximum 5 job descriptions, smoother user experience, and processes that cut down on waiting time. But that's not all – we're diving deep into the AI world, making the most of its cool features. With AI getting better every day, we're making sure you get the latest and greatest in our app. We're also beefing up our data game for super-precise tuning and have some slick new features in the works. Exciting stuff is on the horizon – stay tuned! Visit ResumeGPT to take advantage of what it offers!