Node.js Internals: Libuv and the event loop behind the curtain


Introduction
During Node’s original presentation in 2009, Ryan Dahl’s (i.e. creator of Node) thesis was: “I/O needs to be done differently”.
At the beginning of the talk, he gives a simple example of a program that does a database query, something very usual in server applications.

His question was: “What is your web framework doing while this line of code is running?”
In many cases the execution thread is doing nothing, it just sits there and blocks, waiting for the response. To give a more detailed explanation of the costs of I/O compared to other latencies in the system, he presents the following slide:

During a normal database query, a program has to communicate with the database server (we suppose that the database is located in a remote server). Then, in the worst-case scenario, the database server needs to access the disk to get the results. Finally, the result needs to travel back to the program that requested it, via the network. Adding all this latency, we get hundreds of millions of CPU cycles, which can be better used by the running software instead of blocking and waiting for the result.
To continue the argument, the presentation goes on with the classical comparison between two of the most popular web-servers, Nginx, and Apache.
To give a little background, Apache had been dominating the Web for almost 15 years at the time this presentation was made. Nginx, on the other hand, was relatively newer (since 2004) and was built to solve all the problems that Apache was facing.
If we go into detail, Apache now supports many modes of operation, but initially, it handled new requests by forking new processes (with one thread per process). The amount of overhead that was added by operating this way was huge (a lot of memory used and too much context-switching). To make things simpler, Apache later introduced Apache MPM worker, which is similar, but now each connection was handled by a single thread instead of a whole process. Although it improves performance, handling tens of thousands of concurrent connections by using multithreaded web-servers is difficult and this is why Apache started to struggle.
Nginx, on the other hand, was created to overcome these issues and was based on an asynchronous, non-blocking event-driven architecture. It uses a master process and a small group of worker processes to handle requests. The master process performs privileged operations and spawns worker processes. There are two child processes that handle caching, whereas all the other worker processes deal with incoming connections, disk I/O, etc. Ideally, Nginx will use as many worker processes as there are CPU cores, so the CPU utilization is perfect. If we go into further details, each worker process is single-threaded. It continuously waits for new connections on the listen sockets (each new connection emits a new event). When a new connection arrives, the worker process will create a new connection socket with the client and store the socket handler in a table. A new event that is emitted on the newly created connection socket means that this client has requested something (e.g. read/write to the disk, network I/O, etc…). The worker process will handle this request. If it is a blocking request (e.g. file I/O), a few auxiliary threads will be used, so the main thread is never blocked. While blocking I/O is done, the worker process can go on and listen for new requests. In conclusion, the benefit of this approach is that it uses very few resources and avoids context-switching. With the right system tuning, Nginx can handle hundreds of thousands of concurrent connections per worker thread. More info can be found here.
Going back to the presentation, benchmark results show that Nginx outperforms Apache when it comes to concurrency (since it avoids frequent context-switching), but it’s memory management where Nginx really excels (since there are no processes/threads per connection).
To conclude this introduction, Dahl believed that threaded concurrency is a leaky abstraction. There are locking problems, memory problems, etc…
The presentation continues explaining how Node.js overcomes these problems and the solution is heavily based on Nginx’s architecture. So, Node, like Nginx, is asynchronous, event-driven, and non-blocking. It is single-threaded and it uses an event loop to handle requests. The event loop and all the application code is executed on the main thread. All the heavy tasks (e.g. blocking file I/O, network I/O, encryption, compression, etc…) are done on the operating system’s kernel or in a thread pool (if there is no other choice). Most of this work is done by Libuv.
Libuv: Design overview and features
Libuv is a cross-platform support library written in C. It was originally written to support Node.js, but now it is also used in Julia, Luvit, Neovim, etc… It is designed around the asynchronous event-driven model.
Features
Some of Libuv’s most important functionalities include:
- Full-featured event loop backed by epoll, kqueue, IOCP, event ports
- TCP sockets, which in Node represent the net module.
- DNS resolution (part of the functions inside the dns module are provided by Libuv and some of them are provided by c-ares)
- UDP sockets, which represent the dgram module in Node
- File I/O which include file watching, file system operations (basically everything inside fs module in Node)
- Child processes (the child-process module in Node)
- A pool of worker threads to handle blocking I/O tasks (also since Node 10.5 the worker-threads module is available to execute Javascript in parallel)
- Synchronization primitives for threads (e.g. locks, mutexes, semaphores, barriers)
- High-resolution clock (if Date.now is not accurate enough, process.hrtime can be used)
Architecture
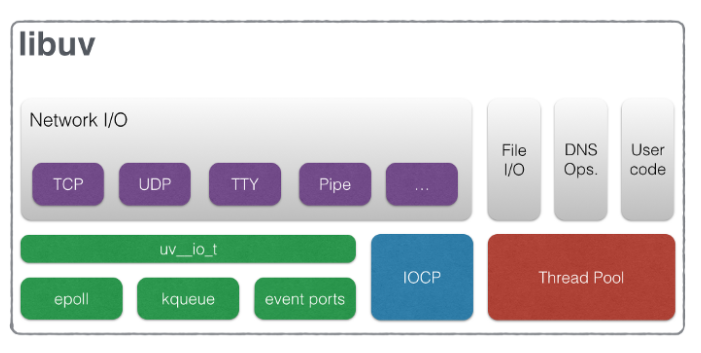
The high-level architecture of Libuv, as shown in the diagram above, can be seen as two layers. The top layer, which includes network I/O, file I/O, DNS operations, and user code, represents the API that can be used by Libuv’s clients. The bottom layer represents the code that handles the I/O polling and the worker threads. IOCP handles I/O polling on Windows. Epoll, Kqueue, and event ports handle I/O polling on Unix systems (epoll is used on Linux, kqueue on BSD, event ports on Solaris).
A few other important concepts in Libuv are:
- Handles: These are abstractions for resources (i.e. entities which are able to do a certain type of work). Some examples of handles are TCP and UDP sockets, timers, signals, child processes. When a job is finished, handles will invoke the corresponding callbacks. As long as a handle is active (i.e. referenced), the event loop will continue running.
- Requests: Abstractions for short-lived operations. According to this presentation, handles can be considered as objects, whereas requests can be thought of as functions or methods (sometimes requests operate on handles, but not always). Like handles, active requests will keep the event loop alive.
- Thread pool: As it was mentioned before, Libuv delegates all the heavy work to a pool of worker threads. The thread pool takes care of the file I/O and DNS lookup. All the callbacks, however, are executed on the main thread. Since Node 10.5, worker threads can also be used by the programmer to execute Javascript in parallel. By default, Libuv uses four threads, but this can be changed using the UV_THREADPOOL_SIZE environment variable.
The event loop
The event loop is the central part of Libuv and it runs on the main thread. It is a semi-infinite loop. It keeps running until there is still some work to be done (e.g. unexecuted code, active handlers, or requests), and when there is no more work the loop exists (process.exit).
The way Libuv and the event loop work is based on the Reactor Pattern. In this pattern, there is an Event queue and an Event demultiplexer. The loop (i.e. the dispatcher) keeps listening for incoming I/O and for each new request, an event is emitted. The event is received by the demultiplexer and it delegates work to the specific handler (the way these requests are handled differs for each OS). Once the work is done, the registered callback is enqueued on the Event queue. Then the callbacks are executed one by one and if there is nothing left to do, the process will exit.
This is a very high-level description of the reactor pattern. While it is true that Libuv is based on this, the way it is implemented is very different (like it is stated in this talk).
Firstly, the event demultiplexer is not a single component. It is actually represented by the I/O polling interface in Libuv’s architecture (epoll, kqueue, etc…).
Secondly, there is not one single Event queue. Instead, there are queues for each phase of the event loop, and between each phase, there are also some smaller queues which are reserved for next ticks and resolved promises).
To have a clearer picture of how the event loop works, let’s see the phases in detail:

- At the beginning of every loop iteration, time is calculated, so there is a reference to the “current time”. The result is cached to avoid frequent system calls.
- A check is performed to see whether there is work to be done or not (is the loop alive?). As it has been mentioned before, the loop is considered alive if there are active handles or requests. If not, the loop will exit (process.exit in Node).
- Due timers are run. This phase has its own queue of callbacks, scheduled to be executed via setTimeout or setInterval (in fact, the internal data structure used is not a queue but a min-heap). A block of code scheduled to be executed after 3 seconds (i.e. timeout is 3000) will be executed after 3 or more seconds (the timer expires in 3 seconds, but the callback can be executed a little later, depending on the number of callbacks in the queue).
- Pending callbacks are executed. These are callbacks from previous operations that have completed (e.g. writing on a socket).
- Idle handlers are run (used internally by Libuv).
- Prepare handle callbacks are executed. Prepare handles are run before blocking for I/O.
- I/O happens. This phase is split into many steps.
Firstly, it checks the I/O queue and executes pending callbacks from previously completed I/O jobs (e.g. new connection callbacks, data read callbacks, etc…).
Secondly, it calculates a timeout, which represents how much time the event loop will block and poll for I/O. Now you might wonder, how does Node block if it is supposed to be non-blocking? In fact, the event loop will block and poll for I/O only if there is nothing else to be done (no pending callbacks on the queues), or until the next timer expires. This is exactly what this step does. For more details on how the timeout is actually calculated, here is the Unix Libuv implementation of the function.
Finally, polling for I/O happens. During this phase, all I/O handles that were monitoring a given file descriptor (socket or file) for a read/write that is completed, get their callbacks called. Here is the actual implementation of the Linux version (epoll) of I/O polling. Also, this is a very good talk that explains the I/O polling mechanism in Node’s event loop. - Check handle callbacks are executed, right after I/O polling. In Node, check handles represent all the setImmediate callbacks.
- Close callbacks are executed. These callbacks are scheduled for execution when Libuv disposes of an active handle.
Process.nextTick and resolved promises
The reason why process.nextTick and resolved promises are not included in the event loop diagram, is that they are not part of Libuv at all. We can imagine these callbacks like mini-queues that stand between every phase of the event loop. So, if we call process.nextTick and pass a callback to that, that code will be executed immediately, before the next phase of the event loop. The same stands for resolved promises’ callbacks (though nextTick callbacks have a higher priority than resolved promises). So, whenever we program in Node, we should be careful not to call process.nextTick recursively, since it can block the event loop.
References and other related articles:
- Ryan Dahl: Original Node.js presentation: https://www.youtube.com/watch?v=ztspvPYybIY
- NGINX vs. Apache: Our View of a Decade-Old Question: https://www.nginx.com/blog/nginx-vs-apache-our-view/
- NodeConf EU | A deep dive into libuv: https://www.youtube.com/watch?v=sGTRmPiXD4Y&feature=emb_title
- Libuv design overview: http://docs.libuv.org/en/v1.x/design.html
- Introduction to libuv: What’s a Unicorn Velociraptor? : https://www.youtube.com/watch?v=_c51fcXRLGw
- Node’s Event Loop From the Inside Out by Sam Roberts, IBM: https://www.youtube.com/watch?v=P9csgxBgaZ8
- The Node.js Event Loop, Timers, and process.nextTick(): https://nodejs.org/uk/docs/guides/event-loop-timers-and-nexttick/